StudioVerse UA
Chrome extension that scores the freelance job feed, drafts custom proposals against a template, and tracks every outcome in one shared place.
Quick read
Lead generation here was fully manual. For every job: open it, weigh the green and red flags, read the client's reviews, decide whether it's worth a shot, customize a template, pick the right portfolio examples, edit, send. A full working day got one person roughly 10–15 proposals.
I built a Chrome extension that reads the search feed, scores each job against preset rules, and — for the jobs we pick — drafts a custom proposal (still anchored to a template) using signals from the job and the client. The person edits the final text and confirms the send. One person can now send up to ~100 proposals in 3–4 hours.
Honest framing first: what's proven is throughput — roughly ×6.7. Conversion stayed inside its pre-tool range, not above it. So this isn't a story about better conversion; it's a story about scaling volume without the quality collapse you'd normally get from a 6.7× increase.
Context
The job, done by hand, is a sequence of judgment calls: open a posting, read it for signal (budget, scope clarity, client history, red flags), open the client's review history, decide go/no-go, then — if it's a go — rewrite a template to fit, choose portfolio pieces that match the niche, and send. Each of those steps is fast on its own; stacked across a day, the ceiling is ~10–15 proposals. The bottleneck isn't typing — it's the repeated reading, scoring, and tailoring.
There's almost nothing off the shelf for this. A couple of services position themselves as lead-gen automation for the platform, but as far as I can tell they run roughly what we run under the hood — scrape the job feed, prompt a cover letter (less customizable than ours) — and a human still clicks "submit" on every proposal. That last point isn't a product choice; it's a hard constraint. When I built this, I hit the same wall: the final "submit proposal" click can't be automated. So a fully hands-off, end-to-end flow was never on the table — for them or for me. Everything up to that click is fair game; the click itself stays human.
Solution
Each day the extension reads the search results, pulls each job's signals, and scores how interesting it is against rules I defined — doing what a human reviewer does, much faster, to support the go/no-go call. The score surfaces as a traffic-light badge on each card, so the feed sorts itself by relevance at a glance.
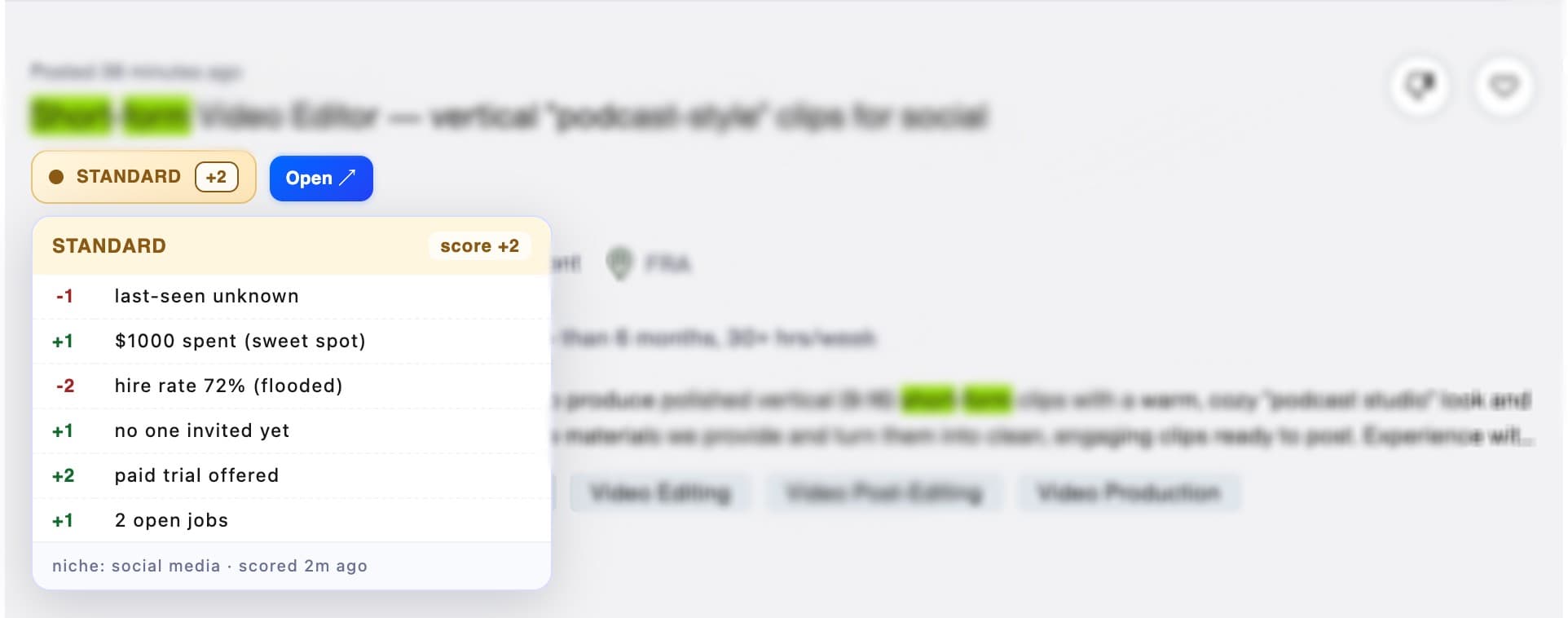
For the jobs we pick, it reads the full description, weighs signals about the job and the client, and drafts a custom proposal — still anchored to a preset template, so the structure stays consistent and on-brand. The person then edits the final text (a safety net for anything off) and confirms the send.
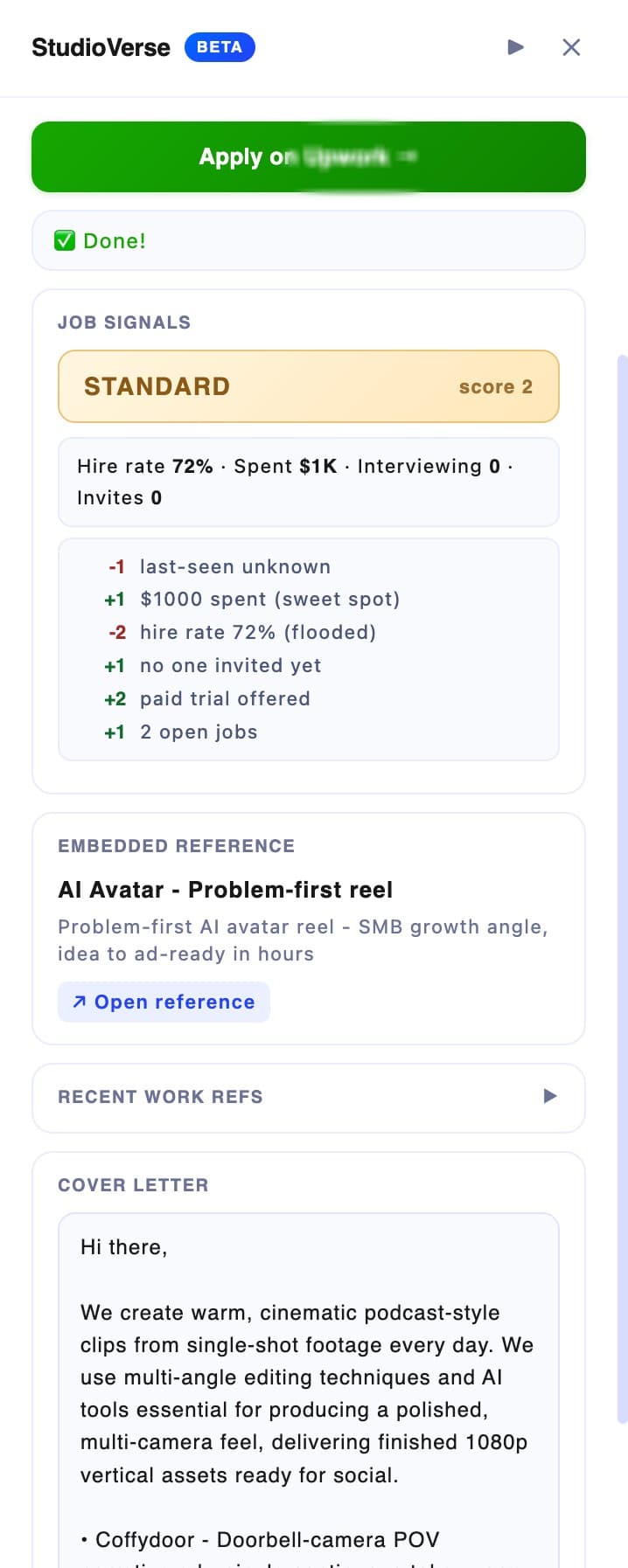
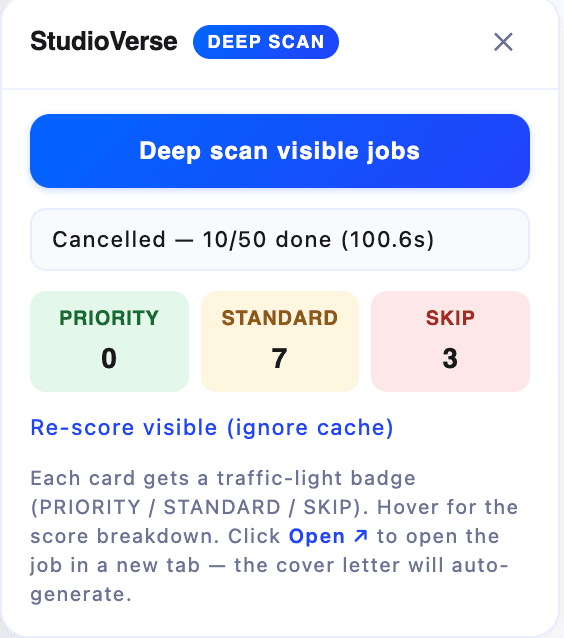
The point isn't to replace the human judgment — it's to do everything around it fast, so the human spends their attention on the decision and the final edit, not on the repetitive reading and drafting.
The hard part
Two problems were the real work.
Encoding the scoring. The interesting question was never "can a model read a job posting" — it's which signals decide whether a job is worth a proposal, and how to express them as rules. Hard filters (jailbreak/spam jobs, niches we deny, per-deliverable rates below our floor) plus weighted soft rules. This is the part where my own lead-gen experience is the input — I was encoding the judgment I'd built by hand into something explicit.
Making the AI output trustworthy. This was the central engineering problem, and it's the same instinct as my Medics tool: where you can't trust the model blindly, wrap it in deterministic rules. A generated proposal can hallucinate — invent a URL, claim a specialty we don't have, drop the required phrase that mirrors the client's language, slip in a banned word. I couldn't put that in front of clients. So every draft passes through 10+ deterministic checks (invented URLs, fabricated specialties, missing mirror phrase, missing closing question, banned/amateur phrasing, and more). Each failure becomes a correction line, fed back to a cheaper model for a targeted retry. The expensive model drafts; the rules decide what's allowed out. AI writes; rules govern.
One product decision inside this is mine and worth naming: the opener for each job has to be maximally custom. A generic opener loses here. My approach is to look at each job from three angles, write an opener variant from each, and then pick the best one. (The mechanism that scores and picks between the three is implementation — see How this was built for where my decisions end and the AI's work begins.)
Impact
Throughput — proven. Manual ceiling was ~15 proposals a day. With the tool, one person sends up to ~100 in 3–4 hours. Roughly ×6.7, and verifiable from our own records. At least three manual steps are gone entirely.
Manual ceiling
~15
proposals / day
With the tool
~100
in 3–4 hours
Throughput
×6.7
proven
Reply rate (of viewed)
14%
after tool
Conversion — the honest part. Before the tool, our numbers swung with whoever was sending and how rushed they were: view rate ran 15–35%, reply rate 2–6%. With the tool, the funnel sits at roughly 30% viewed, 4% replied (of sent), and 14% replied among the proposals that got viewed.
Look at where those land: the after-numbers (30% viewed, 4% replied) fall inside the pre-tool ranges (15–35%, 2–6%). So I won't claim the tool improved conversion — the data doesn't support that. What it shows is that conversion held steady inside its prior band while volume multiplied ~6.7×.
That holding-steady is the actual result. When you push manual volume up 6.7×, conversion usually drops — you rush, you customize less, quality slips. It didn't here, which suggests the per-proposal tailoring survived the scale-up. But this is two people over two months with no controlled comparison, so read it as the honest shape of the thing, not proof: the tool's demonstrated contribution is volume without a quality collapse — not a conversion lift.
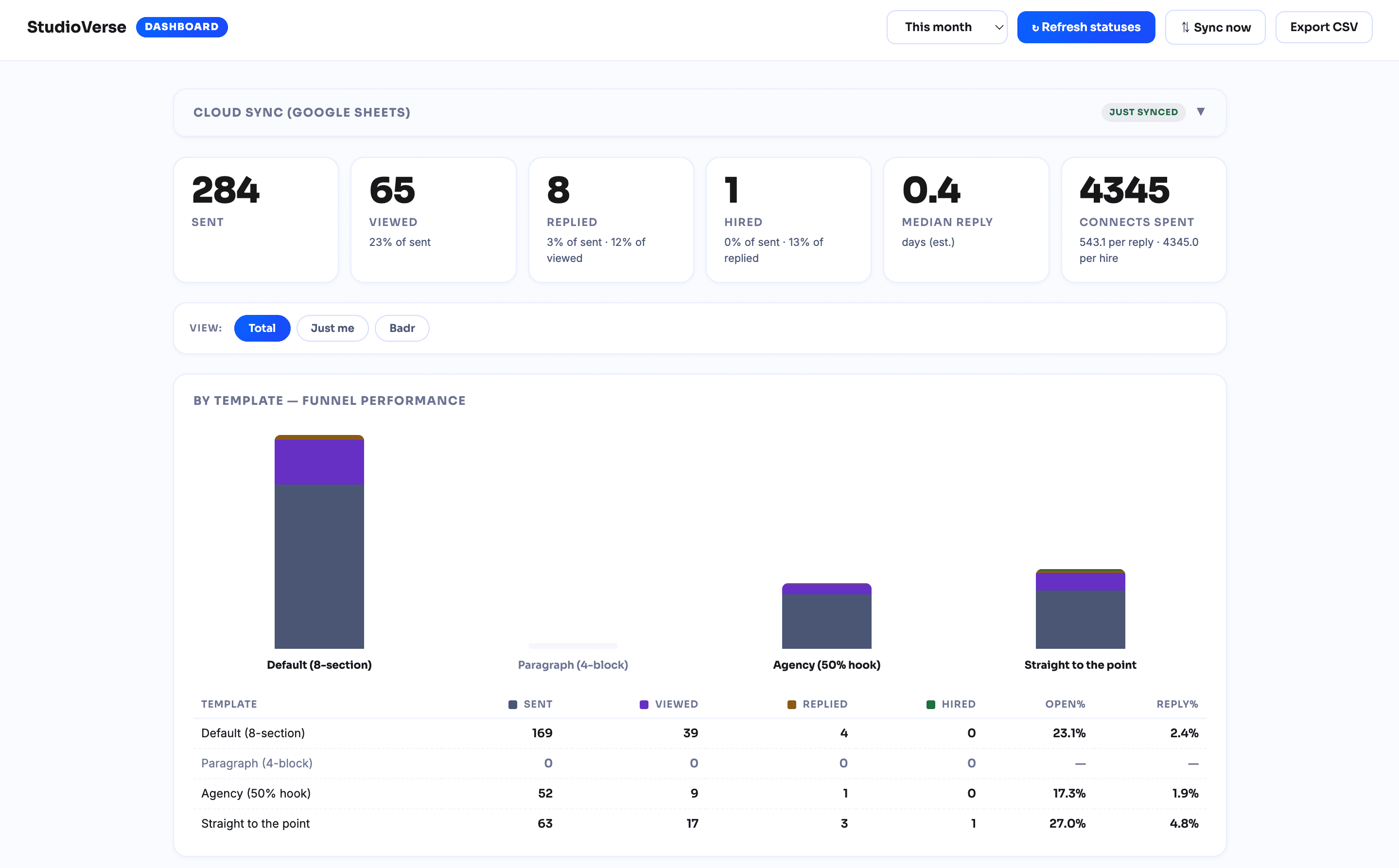
One caveat I'll put here rather than bury: I track connects spent per proposal, so we can see cost per lead and per client. I do not yet fold the AI API cost into that, so our true CAC is incomplete. More in Limitations.
Tech stack & architecture
Vanilla JavaScript (ES2020+), no framework, no build step, no test suite. Chrome Extension Manifest V3. ~10,500 lines across 18 source files.
Frontend
Vanilla JavaScript (ES2020+) · Chrome Extension Manifest V3 · DOM API
Codebase
~10,500 LOC in 18 files · No build step · No test suite
Runtime contexts
Job-page content script (sidebar UI, validator/retry loop) · Search-page content script (per-card MutationObserver scanner) · Service worker (15-min sync alarm)
AI models
Gemini Pro — letter + screening answers · Gemini Flash — opener + judge · Gemini Flash-Lite — analysis + scoring
Storage & sync
chrome.storage.local · Google Apps Script web app · Google Sheet as shared two-person DB
Architecturally, roughly a third of the codebase (the scoring engine, the opener-prompt builders, the portfolio/reference data) is pure logic with no DOM dependency and would port elsewhere; the other two-thirds is bound to the platform's DOM and to Chrome's extension APIs.
What I learned
- If something gets parsed, save it — even when you don't yet know why. Better to have data and no use for it than a use and no data. Half the reason we can analyze the funnel at all today is that I stored everything from the start, before I had a question to ask of it.
- The output is only as trustworthy as the guardrails around it. The model writing the proposal was never the hard part; the validation layer that catches its hallucinations before they reach a client was. Same lesson as encoding regulatory logic by hand in my clinical tool — wrap the model where you can't trust it.
Limitations
These are real and worth stating plainly:
- Short job posts trigger hallucinations. When a posting is too thin, the draft starts inventing to fill the space. I haven't solved this yet.
- No proper A/B tracking. I run theories — prompt tweaks, template changes — but there's no real experimentation system. The template-performance section is a first hint of one, not the real thing. Still building it.
- CAC is incomplete. I track connects per proposal (real cost per lead and per client), but I don't yet include AI API cost, which affects true CAC. Planned.
- The API key is hardcoded. A deliberate tradeoff: this was built for me and one colleague, never for public install. For any public use the key wouldn't sit in the client. I name it so the choice isn't mistaken for an oversight.
- It's stitched onto a third-party site's DOM, so it's brittle by nature. When the platform changes its page, parts break and need patching. That's structural to this kind of tool, not a bug I can close.
- Sync is last-write-wins. If two of us edit the same record between syncs, one silently overwrites the other. Fine for two people; it wouldn't be for more.
Next steps
- A real A/B tracking system for proposal templates and prompts, so improvements are measured rather than assumed.
- Folding AI cost into CAC, for honest unit economics on every lead.
Read next